
Non si tratta di un aggiornamento marginale, ma di un cambio di approccio che potrebbe avere effetti concreti su tutto l’ecosistema delle AI multimodali, quelle capaci di leggere contemporaneamente immagini e testo. Il progetto si chiama RubiCap ed è stato sviluppato insieme all’Università del Wisconsin-Madison, con un obiettivo chiaro: rendere le descrizioni delle immagini più precise, dettagliate e affidabili senza dover ricorrere a modelli giganteschi.
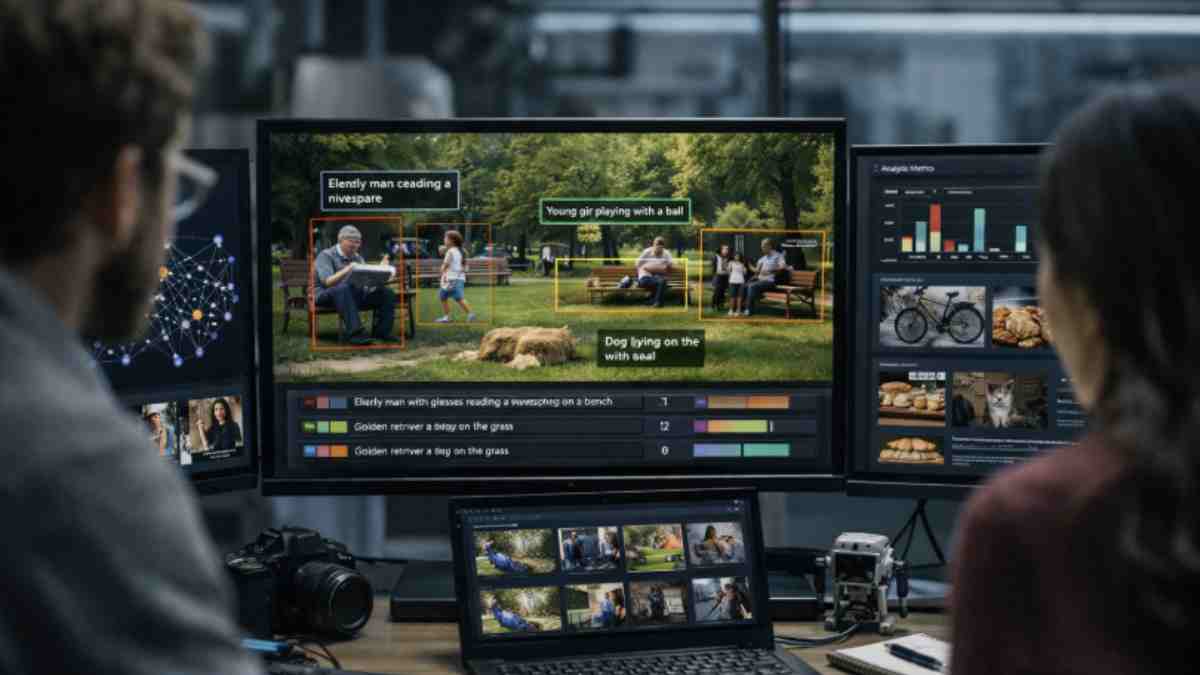
A prima vista può sembrare banale: una foto è una foto, basta dire cosa c’è dentro. In realtà il problema è molto più complesso. La sfida si chiama dense image captioning, cioè la capacità di descrivere non l’immagine nel suo insieme, ma ogni singolo elemento che la compone.
Non più “un parco con persone”, ma una mappa dettagliata della scena: chi è seduto, chi sta camminando, quali oggetti sono presenti, dove si trovano. È una differenza enorme, soprattutto per applicazioni concrete come la ricerca visiva, gli assistenti per non vedenti o l’addestramento dei modelli più avanzati.
Il limite, finora, è sempre stato lo stesso: i dati. Le annotazioni umane costano molto e non sono scalabili, mentre le descrizioni generate automaticamente da altri modelli tendono a essere ripetitive e poco affidabili.
Come funziona RubiCap (e perché è diverso)
La svolta introdotta da RubiCap sta nel modo in cui viene costruito il “feedback” durante l’addestramento.
Invece di affidarsi a una singola risposta considerata corretta, il sistema mette a confronto più punti di vista. Per ogni immagine vengono generate diverse didascalie usando modelli avanzati come Gemini 2.5 Pro, GPT-5 e Qwen2.5 VL 72B Instruct. Parallelamente, il modello in addestramento produce la sua versione.
A questo punto entra in gioco un secondo livello di analisi: un modello valuta tutte le descrizioni, individua cosa è corretto, cosa manca e cosa è impreciso, trasformando queste differenze in criteri oggettivi di qualità.
Infine, un ulteriore sistema assegna punteggi dettagliati, creando un segnale di apprendimento molto più ricco rispetto ai metodi tradizionali. In pratica, l’AI non impara da una sola risposta “giusta”, ma da un confronto continuo tra alternative.

Da questo processo sono nati tre modelli: RubiCap 2B, 3B e 7B. Numeri che, nel mondo dell’intelligenza artificiale, indicano dimensioni relativamente contenute.
Nei test comparativi, questi modelli hanno superato sistemi molto più grandi, arrivando a competere – e in alcuni casi battere – modelli con oltre 70 miliardi di parametri. Non solo: hanno mostrato una maggiore precisione, meno errori e una capacità superiore di evitare le cosiddette “allucinazioni”, cioè descrizioni inventate o inesatte.
Il dato più sorprendente riguarda il modello da 3 miliardi di parametri, che in alcuni benchmark ha fatto meglio della versione più grande. Un segnale chiaro: la qualità dell’addestramento può contare più della dimensione pura.
Perché questa tecnologia conta davvero
Al di là dei numeri, RubiCap apre una strada concreta: sviluppare AI più efficienti, meno costose e allo stesso tempo più affidabili.
Questo significa strumenti di accessibilità più precisi, motori di ricerca visiva più intelligenti e applicazioni quotidiane che riescono davvero a interpretare ciò che vedono, non solo a descriverlo superficialmente.
È anche un messaggio per l’intero settore: la corsa ai modelli sempre più grandi potrebbe non essere l’unica direzione possibile. Esiste un’alternativa fatta di ottimizzazione, metodo e qualità del dato.
E mentre l’intelligenza artificiale continua a entrare nelle nostre vite, il vero salto non sarà solo quanto è potente, ma quanto riesce a capire davvero ciò che ha davanti.